DeepSeek V4-Pro 75% Price Cut Made Permanent: The AI API Pricing War Just Escalated
DeepSeek permanently slashes V4-Pro prices by 75% to $0.87/M output tokens, undercutting GPT-5.5 by 34.5× and Claude Opus 4.7 by 28.7×. Analyze the cost showdown, why it's sustainable, and what it means for developers.
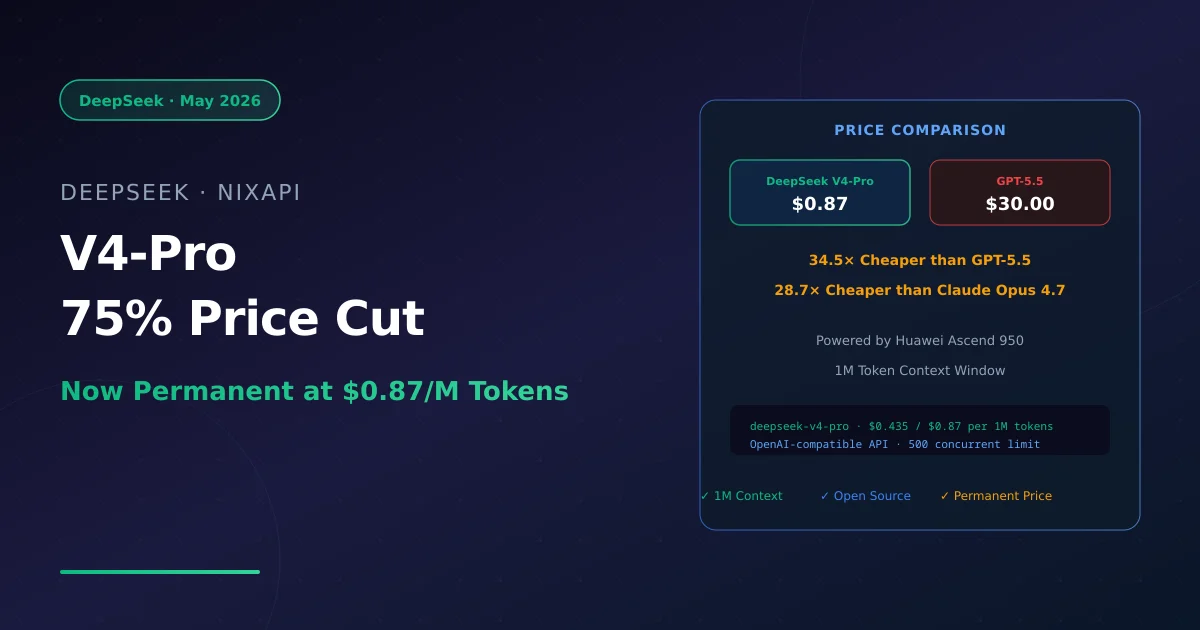
On May 23, 2026, DeepSeek removed the expiration date from its V4-Pro promotional pricing—making the 75% discount permanent. What was set to expire on May 31 at 15:59 UTC is now the standard rate card.
The numbers are stark. V4-Pro output tokens now cost $0.87 per million, down from $3.48. Compare that to GPT-5.5 at $30/M and Claude Opus 4.7 at $25/M—a 34.5× and 28.7× gap respectively. For context workloads above 272K tokens, the gap against GPT-5.5 stretches beyond 50×.
This is not a temporary promotion. This is a structural shift in the cost of frontier AI inference.
The New Price Card
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Cache Hit |
|---|---|---|---|
| DeepSeek V4-Pro | $0.435 | $0.87 | $0.003625 |
| DeepSeek V4 Flash | $0.14 | $0.28 | $0.0028 |
| Google Gemini 3.5 Flash | $0.15 | $0.60 | N/A |
| OpenAI GPT-5.5 | $5.00 | $30.00 | $0.50 |
| Anthropic Claude Opus 4.7 | $5.00 | $25.00 | $0.50 |
Data sourced from official pricing pages as of May 27, 2026. via Artificial Analysis, DeepSeek Pricing.
DeepSeek V4-Pro now sits on a price-performance frontier that western labs cannot easily match. Running the full Artificial Analysis Intelligence Index benchmark costs $268 on V4-Pro versus approximately $3,216 on GPT-5.5 and $5,092 on Opus 4.7—a 12× to 19× cost differential.
Why DeepSeek Can Sustain This
Three structural advantages let DeepSeek lock in these prices where competitors cannot.
1. Huawei Ascend 950 Hardware V4 is the first DeepSeek model family tuned for Huawei’s Ascend accelerators rather than Nvidia GPUs. Huawei aims to ship approximately 750,000 Ascend 950PR units in 2026. This domestic silicon supply chain decouples DeepSeek from Nvidia’s pricing power. At V4’s launch in April, DeepSeek warned V4-Pro could cost up to 12× more than V4 Flash due to “constraints in high-end compute capacity.” Saturday’s announcement signals that supply constraint has materially eased.
2. MoE Architecture Efficiency V4’s sparse 1.6T-parameter Mixture-of-Experts architecture activates only a fraction of the network per token. Combined with its compressed-attention mechanism—which dramatically reduces KV-cache memory pressure at long contexts—the per-token inference cost is structurally lower than dense models from competitors.
3. No IPO Pressure Unlike OpenAI (targeting a ~$300B valuation IPO) and Anthropic (in late-stage fundraising), DeepSeek operates without public-market revenue pressure. It treats inference as a commodity input, not a premium product. Pricing to capture market share is a strategy Western labs cannot pursue without diluting their valuation narratives.
Context Length as the Killer Feature
V4-Pro supports a 1-million-token context window at the new pricing. This transforms cost calculations for document analysis, legal review, codebase comprehension, and conversational history workloads—applications where token consumption compounds rapidly.
At $0.003625 per million tokens on cache-hit input, a system that reuses large prompt prefixes (common in support bots, code assistants, and retrieval agents) achieves near-negligible input costs. The total cost of ownership for a long-context application shifts dramatically in DeepSeek’s favor.
The Accusation: Distillation Attacks
Anthropic has publicly accused DeepSeek of engaging in “distillation attacks”—improperly training on Claude’s outputs. If substantiated, the price gap partly reflects IP arbitrage rather than pure engineering efficiency. However, DeepSeek’s decision to open-source V4 weights provides an independent verification path: the architecture and training methodology are publicly inspectable.
For developers, the pragmatic calculus remains: at these prices, V4-Pro is worth evaluating regardless of provenance.
What This Means for Developers
Immediate Actions (Today)
1. Add DeepSeek as a cost-tier router DeepSeek’s API uses OpenAI-compatible format. Adding a fallback route is minimal code:
import openai
client = openai.OpenAI(
base_url="https://api.deepseek.com",
api_key="your-deepseek-key"
)
# Route non-critical tasks to V4 Flash at $0.28/M output
response = client.chat.completions.create(
model="deepseek-v4-flash",
messages=[{"role": "user", "content": prompt}]
)
2. Audit your token budget If your application processes long documents or maintains conversation history, model the cost delta between your current provider and DeepSeek V4-Pro for your actual usage patterns. At 35–50× price differences, the savings may fund additional product investment.
Strategic Considerations
3. Leverage 1M context as a product differentiator If you build document analysis, legal review, or code analysis tools, DeepSeek’s 1M context at commodity pricing is a competitive advantage that dense-model rivals cannot immediately match. Consider marketing this explicitly.
4. Monitor the supply chain risk DeepSeek’s pricing depends on Huawei Ascend 950 supply. 750,000 units in 2026 is ambitious; supply chain disruptions could pressure prices upward. Build API gateway-level cost monitoring and multi-provider fallback from day one.
The Bigger Picture: AI Market Stratification
The Karpathy-to-Anthropic move and DeepSeek’s permanent price cut are two sides of the same coin. Frontier models (GPT-5.5, Claude Opus, Mythos) are being pulled toward government-class cybersecurity and enterprise premium—where prices stay high. Commodity models (DeepSeek V4, Gemini Flash) are being pushed toward zero-margin inference.
The developer strategy is clear: use commodity models at DeepSeek prices for volume inference, reserve frontier models for the subset of tasks where output quality justifies the 35× premium, and build the routing layer yourself. NixAPI’s multi-provider gateway architecture directly supports this pattern—one integration, automatic cost-tier routing.
References
- DeepSeek V4 Pro API Pricing
- The Next Web: DeepSeek Made Its 75% Discount Permanent
- Artificial Analysis: Intelligence Index Benchmark Costs
- InfoWorld: DeepSeek’s Steep V4-Pro Price Cut Escalates AI Pricing War
- Computerworld: DeepSeek’s V4-Pro Price Cut Analysis
- TokenMix: Cheapest Frontier LLM API 2026
Try NixAPI Now
Reliable LLM API relay for OpenAI, Claude, Gemini, DeepSeek, Qwen, and Grok with ¥1 = $1 top-up
Sign Up Free