GPT-5.5 (Codename Spud): Deep Dive into Agentic Coding Capabilities and Developer Integration Guide
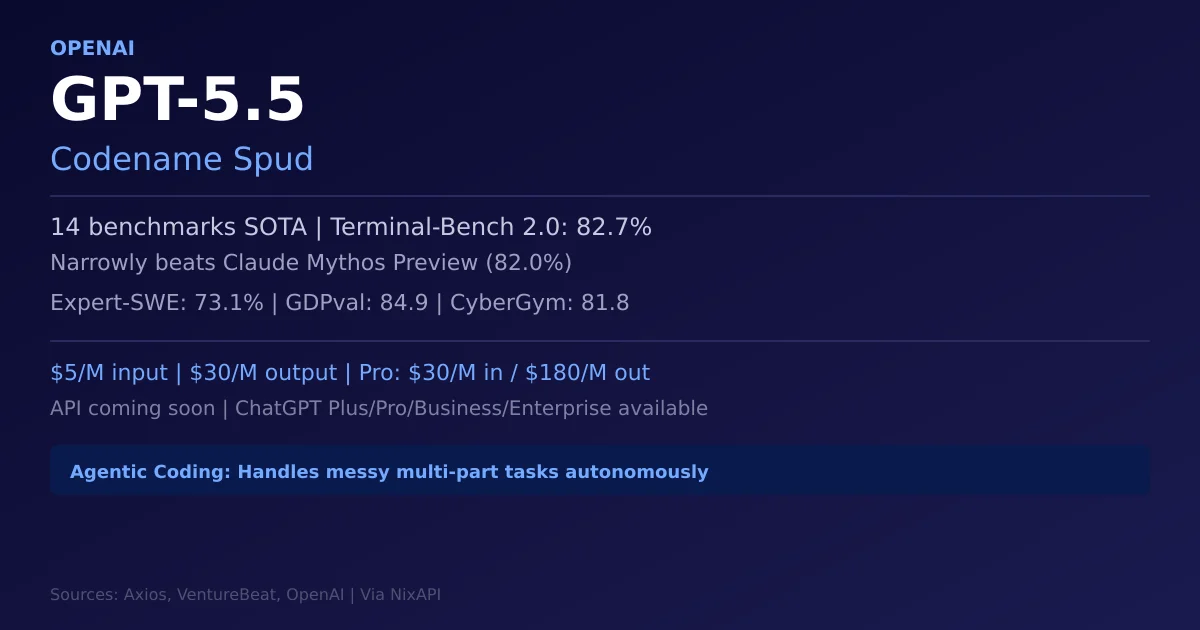
OpenAI released GPT-5.5 (codename Spud) on April 23, 2026, achieving state-of-the-art on 14 benchmarks, with Terminal-Bench 2.0 at 82.7% (narrowly beating Claude Mythos Preview). Greg Brockman calls it extremely good at coding and computer use. API pricing: $5/M input for GPT-5.5, $30/M for GPT-5.5 Pro. API access coming soon. This article covers Agentic Coding capabilities, benchmark data, pricing strategy, and NixAPI integration paths.
Note: Data from Axios (Apr 23 2026), VentureBeat, MacRumors, OpenAI official announcement. All factual claims from public reports.
1. Launch Overview: Codename Spud, Officially GPT-5.5
OpenAI launched GPT-5.5 (internal codename “Spud”) on April 23, 2026 — just one week after Anthropic’s Opus 4.7. GPT-5.5 reclaims the lead for OpenAI in the publicly available model market, achieving state-of-the-art across 14 benchmarks vs. 4 for Claude Opus 4.7 and 2 for Gemini 3.1 Pro.
OpenAI co-founder Greg Brockman on the pre-launch press call:
“What is really special about this model is how much more it can do with less guidance. It’s way more intuitive to use. It can look at an unclear problem and figure out what needs to happen next.”
CEO Sam Altman on X: “We want our users to have access to the best technology and for everyone to have equal opportunity.”
2. Agentic Coding: The Core Breakthrough
GPT-5.5’s core positioning is not “smarter” but more autonomous — capable of handling ambiguous multi-part tasks that traditionally require step-by-step human guidance.
Benchmark Data
| Benchmark | GPT-5.5 | Claude Opus 4.7 | Gemini 3.1 Pro | Claude Mythos Preview |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 82.7% | 69.4% | 68.5% | 82.0% |
| Expert-SWE (internal, 20hr tasks) | 73.1% | — | — | — |
| GDPval (economic knowledge work) | 84.9 | 80.3 | 67.3 | — |
| CyberGym (cybersecurity) | 81.8 | 73.1 | — | 83.1 |
| FrontierMath Tier 4 | 35.4 | 22.9 | 16.7 | — |
| OSWorld-Verified | 78.7 | 78.0 | — | 79.6 |
| SWE-bench Pro (public) | 58.6% | 64.3% | 54.2% | 77.8% |
| Humanity’s Last Exam (no tools) | 43.1% | 46.9% | — | 56.8% |
Terminal-Bench 2.0 is the critical metric: tests a model’s ability to navigate and complete tasks in a sandboxed terminal environment. GPT-5.5 narrowly beats Claude Mythos Preview (82.0%) — a significant achievement for a broadly accessible model.
Early User Feedback
- Dan Shipper (Every CEO): “The first coding model I’ve used that has serious conceptual clarity.” He asked GPT-5.5 to debug a complex system failure that previously required a full team of engineers to rewrite; GPT-5.5 produced the same fix autonomously.
- Pietro Schirano (MagicPath CEO): “A step change in performance” — GPT-5.5 merged a branch with hundreds of refactor changes into main in a single 20-minute pass.
- NVIDIA engineer (anonymous, early access): “Losing access to GPT-5.5 feels like I’ve had a limb amputated.”
3. Architecture: No Latency Tradeoff for Intelligence
GPT-5.5 achieves higher intelligence at the same latency as GPT-5.4:
- Running on NVIDIA GB200 and GB300 NVL72 systems
- OpenAI wrote custom heuristic algorithms (using AI) to partition and balance work across GPU cores
- Token generation speed improved by over 20%
- Deep hardware-software co-design
Brockman: “Larger models typically suffer from increased latency. GPT-5.5 matches GPT-5.4’s per-token latency while delivering a higher level of intelligence.”
4. Pricing: Two-Tier Strategy, API Coming Soon
| Model | Input tokens | Output tokens |
|---|---|---|
| GPT-5.4 | $2.50 / 1M | $15 / 1M |
| GPT-5.5 | $5 / 1M | $30 / 1M |
| GPT-5.5 Pro | $30 / 1M | $180 / 1M |
GPT-5.5 is 2× GPT-5.4; Pro is 6× standard. OpenAI emphasizes GPT-5.5 is more “token efficient” — fewer tokens to complete the same task.
API not yet broadly available. OpenAI states: “API deployments require different safeguards and we are working closely with partners and customers on safety and security requirements.” Expected “very soon.”
5. Security: Cyber-Permissive License
Under OpenAI’s Preparedness Framework, GPT-5.5 is classified “High” risk for biological and cybersecurity capabilities. “Trusted Access for Cyber” introduces:
- General users: Strict cyber-risk classifiers limiting security-related prompts
- Verified defenders (critical infrastructure operators): Can apply for “cyber-permissive” license with fewer restrictions
6. NixAPI Integration
// providers/gpt-55.ts
export const gpt55 = createOpenAICompatibleClient({
baseURL: 'https://api.openai.com/v1',
apiKey: process.env.OPENAI_API_KEY,
defaultModel: 'gpt-5.5',
});
export const gpt55Pro = createOpenAICompatibleClient({
baseURL: 'https://api.openai.com/v1',
apiKey: process.env.OPENAI_API_KEY,
defaultModel: 'gpt-5.5-pro',
});
// NixAPI routing
export async function routeAgenticTask(task: AgenticTask) {
// High-stakes tasks -> GPT-5.5 Pro (when API available)
if (task.type === 'legal-research' || task.type === 'data-science') {
return gpt55Pro.chat(task.messages, { reasoning: { effort: 'high' } });
}
// Agentic Coding / Computer Use -> GPT-5.5
if (task.type === 'agentic-coding' || task.type === 'computer-use') {
return gpt55.chat(task.messages, { reasoning: { effort: 'high' } });
}
// Scientific research -> Thinking mode
if (task.type === 'scientific-research') {
return gpt55.chat(task.messages, { reasoning: { effort: 'thinking' } });
}
// Cost-sensitive coding -> Opus 4.7
if (task.costSensitive) {
return opus47.chat(task.messages, { effort: 'xhigh' });
}
return sonnet46.chat(task.messages);
}
7. Key Takeaway
GPT-5.5’s core proposition: same latency as GPT-5.4 with significantly higher autonomy and conceptual clarity. For NixAPI, GPT-5.5 is the top candidate for complex Agentic Coding and Computer Use tasks — but with API not yet broadly available, Claude Opus 4.7 remains the practical choice today, with GPT-5.5 taking over once API access opens.
Try NixAPI Now
Reliable LLM API relay for OpenAI, Claude, Gemini, DeepSeek, Qwen, and Grok with ¥1 = $1 top-up
Sign Up Free